
[Project] Tennis Swing Analysis
Tennis Motion Analysis System
This project is a personal hobby endeavor aimed at creating a system that allows users to upload their own tennis videos, which are then analyzed to distinguish between forehand and backhand motions. The system also provides accuracy feedback by comparing the user’s form to a standard reference and offers suggestions for improvement.
To kickstart this project, I used practice videos of one of my favorite tennis players, Carlos Alcaraz. Using these videos, I extracted joint positions, manually labeled the motions, and trained a model to classify each movement.
Project Overview
Tennis is a sport where recognizing and analyzing complex motions from various angles and speeds is crucial. Identifying and improving specific motions, like forehands and backhands, can offer valuable insights not only for professional players but also for amateurs looking to refine their techniques. The primary goal of this project is to develop a basic system that leverages LSTM (Long Short-Term Memory) networks to learn and analyze motion sequences in real-time or post-playback. In future stages, I plan to experiment with different models to enhance accuracy and select the most effective one for motion improvement.
For this initial stage, I used MediaPipe, a pose estimation model, to extract joint positions from the videos. Using these extracted coordinates, I trained an LSTM model to classify motions, focusing on building a foundational system to distinguish tennis strokes.
Data Preparation
1. Collecting Videos from YouTube
First, I collected practice videos of Carlos Alcaraz from YouTube(Thanks to @Slow-Mo Tennis), slicing into 3 videos, each about 10 minutes long. Each video includes both forehand and backhand strokes, making them suitable for training and testing. I used PyTube to download these videos directly from YouTube.
from pytube import YouTube
def download_video(url, save_path):
yt = YouTube(url)
stream = yt.streams.filter(progressive=True, file_extension='mp4').first()
stream.download(output_path=save_path)
download_video("https://youtu.be/VIDEO_ID", "./tennis_videos")
2. Extracting Poses with MediaPipe
Next, I used MediaPipe’s pose estimation model to process each video, extracting x, y, and z coordinates for key joints in each frame. MediaPipe was selected because of its straightforward setup and ability to quickly capture essential joint information, making it ideal for this project’s initial stages.
import cv2
import mediapipe as mp
mp_pose = mp.solutions.pose
pose = mp_pose.Pose(static_image_mode=False, min_detection_confidence=0.5, min_tracking_confidence=0.5)
cap = cv2.VideoCapture('./tennis_videos/alcaraz_practice.mp4')
landmarks_data = []
while cap.isOpened():
ret, frame = cap.read()
if not ret:
break
image_rgb = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
results = pose.process(image_rgb)
if results.pose_landmarks:
frame_landmarks = [{"x": lm.x, "y": lm.y, "z": lm.z} for lm in results.pose_landmarks.landmark]
landmarks_data.append(frame_landmarks)
3. Manual Labeling of Forehand and Backhand Segments
After extracting the joint coordinates, I used the CVAT annotation tool to manually label each segment as either forehand or backhand. This labeled data was then organized into a dataset suitable for training the classification model.
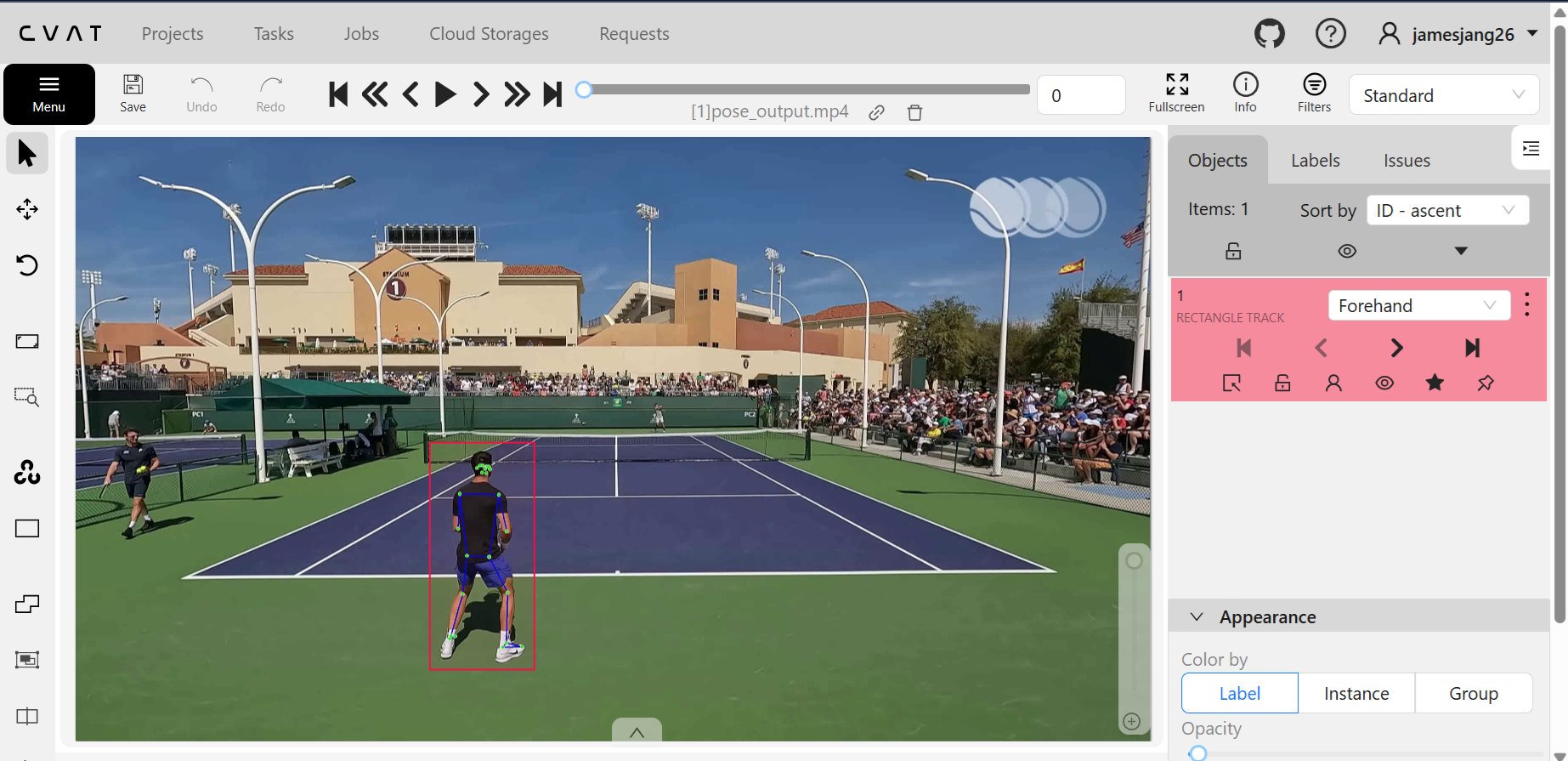
# Example of finalized annotation dataset
[
[
{
"frame_id": 170,
"label": "Backhand",
"landmarks": [
{
"x": 0.45166587829589844,
"y": 0.5477275848388672,
"z": 0.09219522774219513,
"visibility": 0.9998981952667236
},
{
"x": 0.44997501373291016,
"y": 0.5417541265487671,
"z": 0.07722048461437225,
"visibility": 0.9999018907546997
},
# ommited below
]
}
]
]
Model Training
Data Preprocessing
To prepare the data for training, I standardized and padded each sequence so that they were compatible with the model’s input requirements. Using StandardScaler, I normalized each joint coordinate, and padded shorter sequences to ensure consistent input length across all sequences.
import json
import numpy as np
import torch
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from torch.utils.data import DataLoader, Dataset
from google.colab import drive
import joblib
# Mount Google Drive
drive.mount('/content/drive', force_remount=True)
# Define paths to multiple JSON files for each video and annotation
json_paths = [
'/content/drive/My Drive/tennis/[1]combined_sequences.json',
'/content/drive/My Drive/tennis/[2]combined_sequences.json',
'/content/drive/My Drive/tennis/[3]combined_sequences.json'
]
# Load and combine data
X = []
y = []
label_map = {'Forehand': 0, 'Backhand': 1} # Map labels to numeric values
for path in json_paths:
with open(path, 'r') as f:
data = json.load(f)
for sequence in data:
sequence_landmarks = []
for frame_data in sequence:
landmarks = frame_data['landmarks']
# Check if landmarks is a list or dict and flatten accordingly
landmarks_flat = [coord for lm in landmarks for coord in (lm['x'], lm['y'], lm['z'])] if isinstance(landmarks, list) else [value for lm in landmarks.values() for value in (lm['x'], lm['y'], lm['z'])]
sequence_landmarks.append(landmarks_flat)
X.append(sequence_landmarks)
y.append(label_map[sequence[0]['label']])
# Calculate the maximum sequence length for padding
max_seq_length = max(len(seq) for seq in X)
# Pad sequences to ensure they are of the same length
X_padded = np.array([seq + [[0.0] * len(seq[0])] * (max_seq_length - len(seq)) for seq in X], dtype=np.float32)
y = np.array(y)
# Normalize data with StandardScaler and reshape back
scaler = StandardScaler()
X_padded = scaler.fit_transform(X_padded.reshape(-1, X_padded.shape[-1])).reshape(X_padded.shape)
# Save scaler for future use
scaler_path = "/content/drive/My Drive/tennis/scaler.pkl"
joblib.dump(scaler, scaler_path)
print(f"StandardScaler saved at '{scaler_path}'.")
# Split data into train and test sets
X_train, X_test, y_train, y_test = train_test_split(X_padded, y, test_size=0.2, random_state=42)
# Convert to torch tensors
X_train_tensor = torch.tensor(X_train, dtype=torch.float32)
X_test_tensor = torch.tensor(X_test, dtype=torch.float32)
y_train_tensor = torch.tensor(y_train, dtype=torch.long)
y_test_tensor = torch.tensor(y_test, dtype=torch.long)
Model Training Code
I implemented an LSTM model, structured to analyze sequences of poses and classify each segment as either a forehand or a backhand based on the final frame in each sequence.
import torch.nn as nn
import torch.optim as optim
class LSTMModel(nn.Module):
def __init__(self, input_size, hidden_size, output_size, num_layers=1):
super(LSTMModel, self).__init__()
self.lstm = nn.LSTM(input_size, hidden_size, num_layers, batch_first=True)
self.fc = nn.Linear(hidden_size, output_size)
def forward(self, x):
h0 = torch.zeros(1, x.size(0), hidden_size).to(x.device)
c0 = torch.zeros(1, x.size(0), hidden_size).to(x.device)
out, _ = self.lstm(x, (h0, c0))
out = self.fc(out[:, -1, :])
return out
# Model initialization
input_size = X_train_tensor.shape[2]
hidden_size = 64
output_size = 2
model = LSTMModel(input_size, hidden_size, output_size).to(device)
# Training setup
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)
# Train the model
num_epochs = 100
train_loader = DataLoader(TennisDataset(X_train_tensor, y_train_tensor), batch_size=32, shuffle=True)
for epoch in range(num_epochs):
model.train()
running_loss = 0.0
for X_batch, y_batch in train_loader:
X_batch, y_batch = X_batch.to(device), y_batch.to(device)
optimizer.zero_grad()
outputs = model(X_batch)
loss = criterion(outputs, y_batch)
loss.backward()
optimizer.step()
running_loss += loss.item()
print(f"Epoch [{epoch+1}/{num_epochs}], Loss: {running_loss/len(train_loader):.4f}")
# Save the trained model
torch.save(model.state_dict(), "/content/drive/My Drive/tennis/tennis_model.pth")
Testing and Analysis of Results
Visualization of Predictions on Test Videos
Using the trained model, I analyzed a test video by inputting each frame’s joint positions and obtaining a forehand or backhand prediction for each segment. The predictions were visually represented on the video, allowing for straightforward evaluation of the model’s performance.
import cv2
import mediapipe as mp
import joblib
# Load the trained model and scaler
model.load_state_dict(torch.load("/content/drive/My Drive/tennis/tennis_model.pth"))
scaler = joblib.load("/content/drive/My Drive/tennis/scaler.pkl")
# Set up MediaPipe and video paths
mp_pose = mp.solutions.pose
video_path = '/content/drive/My Drive/tennis/[3]pose_output.mp4'
output_video_path = "/content/drive/My Drive/tennis/[3]annotated_video.mp4"
cap = cv2.VideoCapture(video_path)
fourcc = cv2.VideoWriter_fourcc(*'mp4v')
out = cv2.VideoWriter(output_video_path, fourcc, cap.get(cv2.CAP_PROP_FPS),
(int(cap.get(cv2.CAP_PROP_FRAME_WIDTH)), int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT))))
# Annotate video with predictions
with mp_pose.Pose(static_image_mode=False, min_detection_confidence=0.5, min_tracking_confidence=0.5) as pose:
while cap.isOpened():
ret, frame = cap.read()
if not ret:
break
# Extract landmarks
image_rgb = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
results = pose.process(image_rgb)
if results.pose_landmarks:
landmarks_flat = [coord for lm in results.pose_landmarks.landmark for coord in (lm.x, lm.y, lm.z)]
landmarks_array = np.array(landmarks_flat, dtype=np.float32).reshape(1, -1)
landmarks_norm = scaler.transform(landmarks_array)
landmarks_tensor = torch.tensor(landmarks_norm, dtype=torch.float32).unsqueeze(0).to(device)
# Predict using the model
with torch.no_grad():
output = model(landmarks_tensor)
_, predicted = torch.max(output.data, 1)
label = "Forehand" if predicted.item() == 0 else "Backhand"
# Annotate frame
cv2.putText(frame, label, (10, 50), cv2.FONT_HERSHEY_SIMPLEX, 1, (255, 0, 0) if label == "Forehand" else (0, 0, 255), 2)
color = (255, 0, 0) if label == "Forehand" else (0, 0, 255)
cv2.rectangle(frame, (5, 5), (frame.shape[1]-5, frame.shape[0]-5), color, 5)
out.write(frame)
cap.release()
out.release()
print("Annotated video saved to Google Drive:", output_video_path)
Observed Issues and Potential Improvements
- Labeling Only the Joint Area: Currently, labels are applied to the entire frame, which reduces clarity. Focusing the labels on just the joint area would improve the visualization.
- Smoothing Across Segments: Rather than predicting each frame independently, applying segment-based smoothing would improve stability by reducing prediction fluctuations across frames.
- Limited Data Size: The small dataset size limits the model’s ability to generalize across different angles and conditions. Expanding the dataset or using data augmentation would likely enhance model performance.
Conclusion
In this project, I used practice videos of Carlos Alcaraz to train an LSTM model that distinguishes between forehand and backhand motions in tennis. By combining MediaPipe’s pose estimation capabilities with the LSTM model, I created a foundational system that analyzes joint coordinates to predict tennis strokes, with visual feedback provided on the test video.
However, several limitations were identified: (1) the small dataset size, which limited learning, and (2) the model’s tendency to label every frame across the entire screen, rather than focusing on specific joint areas. Moreover, there’s a need to refine the output by adding smoothing to improve the stability of predictions over sequential frames.
Going forward, I plan to improve this system by collecting more data, applying data augmentation techniques, and implementing segment-based smoothing. These enhancements will enable the creation of a more robust and precise tennis motion analysis system.